
The release of Gemini 3.1 Flash-Lite marks a strategic pivot for Google as the company seeks to capture the "efficiency" segment of the AI market. While previous generations of large language models (LLMs) focused almost exclusively on increasing parameter counts and raw reasoning capabilities, the current industry trend has shifted toward optimizing models for specific, high-frequency tasks where latency and cost are the primary constraints. Google’s latest offering aims to provide "best-in-class intelligence" for workloads that involve massive data processing, such as real-time content moderation, large-scale language translation, and the automated generation of user interfaces.
A New Benchmark for Efficiency and Performance
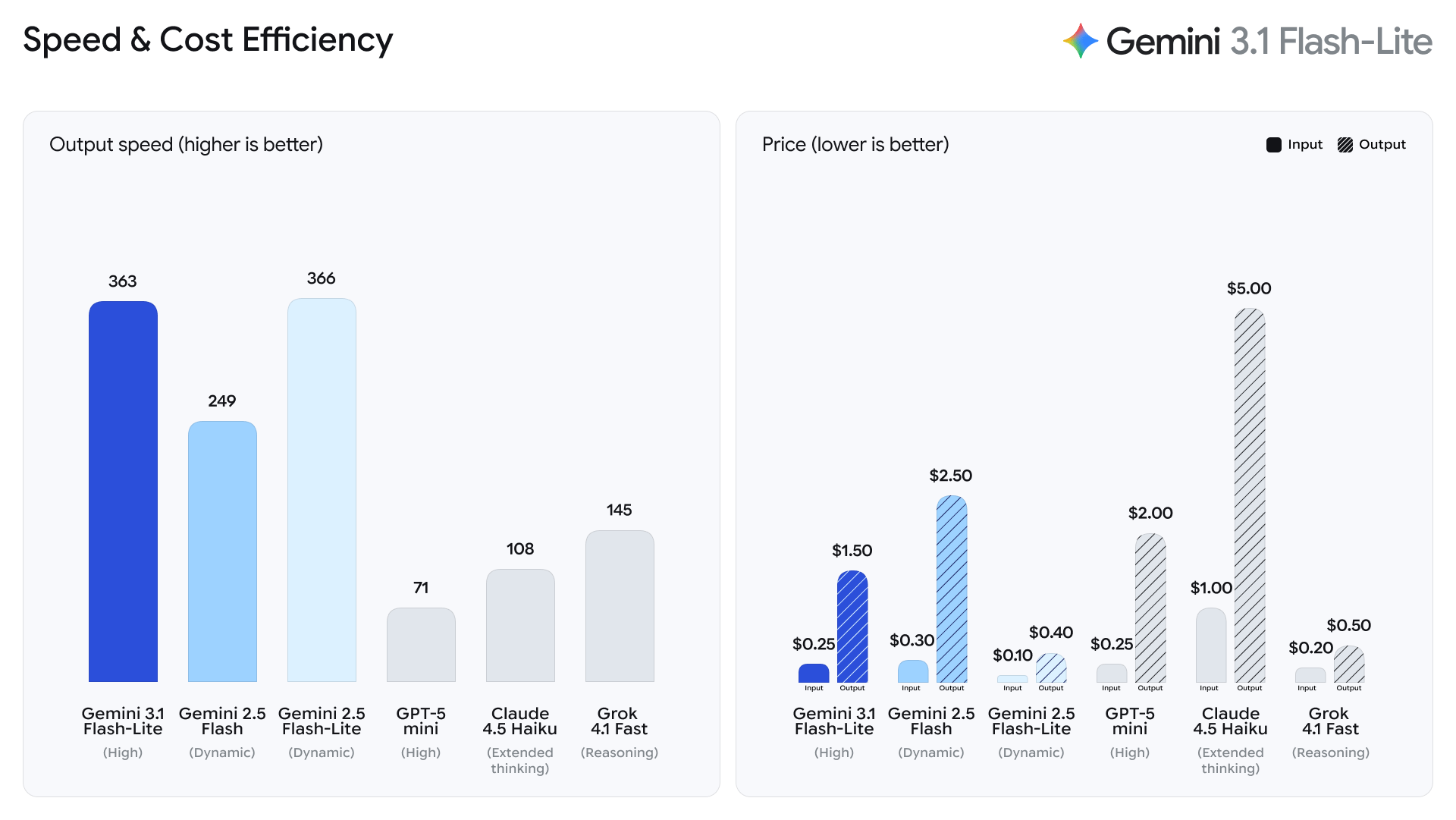
The technical specifications of Gemini 3.1 Flash-Lite suggest a significant leap forward in the optimization of transformer-based architectures. According to data released by Google and verified by the Artificial Analysis benchmark, the 3.1 Flash-Lite model delivers a 2.5X faster Time to First Answer Token (TTFT) compared to its predecessor, the Gemini 2.5 Flash. Furthermore, it boasts a 45% increase in overall output speed. This reduction in latency is critical for developers building responsive, real-time applications where a delay of even a few hundred milliseconds can degrade the user experience.
In terms of pricing, Google has positioned Gemini 3.1 Flash-Lite as one of the most competitive models in its class. The model is priced at $0.25 per one million input tokens and $1.50 per one million output tokens. This aggressive pricing strategy is intended to lower the barrier to entry for startups and enterprises that need to process billions of tokens daily but have been deterred by the prohibitive costs of larger models like Gemini 1.5 Pro or GPT-4o. By offering a "Lite" version that retains high reasoning capabilities, Google is effectively commoditizing high-tier intelligence for mass-market deployment.
Technical Benchmarks and Comparative Analysis
Despite its "Lite" designation, Gemini 3.1 Flash-Lite has demonstrated robust performance across a variety of standardized AI benchmarks. On the Arena.ai Leaderboard (formerly known as the LMSYS Chatbot Arena), which utilizes a crowdsourced Elo rating system to rank model capabilities based on human preference, Gemini 3.1 Flash-Lite achieved an impressive score of 1432. This score places it in direct competition with much larger models from previous generations, suggesting that Google has successfully distilled complex reasoning capabilities into a smaller, faster package.

The model’s performance in specialized domains is equally noteworthy. In the GPQA (Graduate-Level Google-Proof Q&A) Diamond benchmark, which tests advanced reasoning in science and logic, the model achieved a score of 86.9%. In the MMMU Pro (Massive Multi-discipline Multimodal Understanding) benchmark, it scored 76.8%. These figures indicate that the model is not merely a text processor but a multimodal engine capable of understanding complex visual and logical inputs. Remarkably, these scores surpass those of the Gemini 2.5 Flash, proving that the 3.1 architecture represents a genuine evolution in model density and intelligence.
The Evolution of the Gemini Ecosystem: A Brief Chronology
The debut of Gemini 3.1 Flash-Lite is the latest milestone in a rapid release cycle that began in late 2023. To understand the significance of this model, it is necessary to look at the timeline of Google’s AI development:
- December 2023: Google introduces the Gemini 1.0 series, featuring Ultra, Pro, and Nano versions. This marked the company’s first major step into natively multimodal models.
- February 2024: The Gemini 1.5 series is announced, introducing the industry-first "long context window" of up to one million tokens, later expanded to two million.
- May 2024: Google launches Gemini 1.5 Flash at the I/O developer conference, emphasizing speed and efficiency for the first time.
- Late 2024: The Gemini 2.0 and 2.5 series roll out, further refining the balance between multimodal capabilities and reasoning speed.
- March 2025: The introduction of the Gemini 3 series, led by Gemini 3.1 Flash-Lite, signals a move toward "intelligence at scale," where the focus is on maximizing the utility of every dollar spent on compute.
This chronology illustrates a clear trajectory: Google is no longer just trying to build the "smartest" model in a vacuum; it is building a specialized toolkit where developers can choose the exact level of intelligence and speed required for their specific use case.
Adaptive Intelligence and Developer Control
One of the standout features of Gemini 3.1 Flash-Lite is the introduction of "Adaptive Thinking Levels." Available within Google AI Studio and Vertex AI, this feature allows developers to exert granular control over the model’s cognitive processes. For simple tasks, such as basic data categorization or sentiment analysis, the model can be set to a "low-thought" mode, which maximizes speed and minimizes cost. For more complex assignments, such as generating code for a SaaS dashboard or simulating economic models, developers can increase the thinking level, allowing the model to perform more internal reasoning steps before providing an output.
This flexibility is particularly valuable for "high-frequency workloads." In traditional AI deployments, a single model tier often has to handle both simple and complex queries, leading to inefficiencies. With Gemini 3.1 Flash-Lite, a developer can programmatically adjust the model’s intensity based on the complexity of the incoming request. This ensures that resources are never wasted on over-processing simple tasks, while still maintaining the precision required for nuanced instructions.

Industry Adoption and Real-World Applications
Early-access testers and enterprise partners have already begun integrating Gemini 3.1 Flash-Lite into their production environments. The feedback from these early adopters highlights the model’s ability to maintain high instruction-following adherence even at extreme speeds.
Kolby Nottingham, a representative from the gaming and simulation company Latitude, noted that the model’s speed and instruction-following capabilities allow for more immersive and responsive AI-driven narratives. Similarly, Andrew Carr at Cartwheel highlighted the model’s multimodal labeling capabilities, which allow the company to process and tag vast amounts of visual data with the speed required for modern digital asset management.
In the fashion and retail sector, Bianca Rangecroft of Whering reported that the model has been instrumental in consistent item tagging and data labeling. For a company managing millions of individual clothing items, the cost-to-performance ratio of Flash-Lite provides a sustainable path for growth that was previously unattainable with more expensive model tiers. Meanwhile, Kaan Ortabas at HubX emphasized that the transition to Gemini 3.1 Flash-Lite resulted in immediate performance metrics improvements and a significant reduction in operational overhead.
Broader Impact and Market Implications
The release of Gemini 3.1 Flash-Lite has broader implications for the global AI market. By lowering the cost of high-quality inference, Google is accelerating the "democratization" of AI. Small-to-medium enterprises (SMEs) that previously lacked the budget for enterprise-grade AI can now implement sophisticated automation.
Furthermore, this move puts pressure on other major players in the industry, such as OpenAI and Anthropic, to continue optimizing their "mini" and "haiku" model tiers. The competition is no longer just about who has the most powerful supercomputer, but who can deliver the most "intelligence per watt" and "intelligence per cent."

From a technical standpoint, the success of Flash-Lite suggests that the industry may be reaching a point of diminishing returns for massive parameter scaling. Instead, the focus is shifting toward architectural efficiency—finding ways to achieve "Ultra-level" results with "Lite-level" resource consumption. This shift is essential for the long-term sustainability of the AI industry, particularly as concerns regarding the energy consumption of data centers continue to grow.
Future Outlook for the Gemini 3 Series
As Gemini 3.1 Flash-Lite moves from preview to general availability, Google is expected to integrate these efficiencies across the rest of its workspace and cloud ecosystem. The "Flash" philosophy is likely to become the standard for the majority of consumer-facing AI interactions, while the "Pro" and "Ultra" tiers will be reserved for the most demanding scientific and creative endeavors.
For developers, the message from Google is clear: the era of choosing between "smart" and "fast" is coming to an end. With Gemini 3.1 Flash-Lite, Google is betting that the future of AI lies in high-volume, low-latency intelligence that can be deployed at a massive scale without compromising on quality. As more companies move their experimental AI projects into full-scale production, the demand for models like Flash-Lite is expected to surge, further solidifying Google’s position in the increasingly competitive landscape of generative artificial intelligence.
