

The launch of Gemini 3.1 Flash Live marks a significant milestone in the evolution of conversational artificial intelligence, signaling a shift from text-centric interfaces to fluid, voice-first interactions. Developed by Google’s Gemini team, this latest audio and voice model is engineered to address the persistent challenges of latency, tonal nuance, and reasoning in real-time dialogue. By optimizing the model for speed without sacrificing precision, Google aims to provide a more intuitive experience for a broad spectrum of users, ranging from independent developers and large-scale enterprises to everyday consumers utilizing Gemini-powered mobile applications.
The Technological Evolution of the Gemini Ecosystem
To understand the significance of Gemini 3.1 Flash Live, it is necessary to examine the trajectory of Google’s AI development over the past year. Following the introduction of the Gemini 1.0 series, Google rapidly iterated with the 1.5 Pro and 1.5 Flash models, which introduced the concept of a "long context window" and multimodal native capabilities. While previous iterations allowed the model to process audio as data, Gemini 3.1 Flash Live is specifically tuned for the "Live" experience—a state where the AI must listen, think, and speak simultaneously with minimal delay.
The "Flash" designation within Google’s hierarchy refers to models optimized for high-volume, low-latency tasks. Gemini 3.1 Flash Live builds upon this foundation by refining the model’s ability to handle the "rhythm" of human conversation. Unlike standard text-to-speech engines that often sound robotic or struggle with timing, this new model is designed to recognize when a user is pausing for thought versus when they have finished their sentence. This advancement is critical for reducing the awkward "double-talk" that frequently occurs in voice-over-IP (VoIP) and AI-human interactions.

Benchmarking Performance: Precision and Reasoning
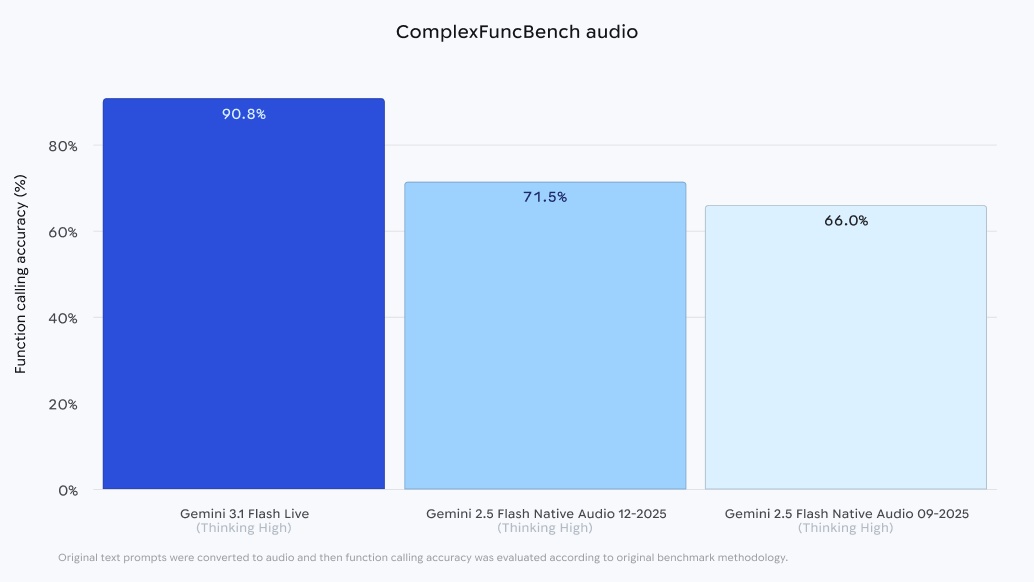
Google has released several data points indicating that Gemini 3.1 Flash Live outperforms its predecessors and competitors in key areas of audio processing and task execution. One of the primary metrics cited is the model’s performance on the ComplexFuncBench Audio benchmark. This specific test evaluates an AI’s ability to perform multi-step function calling—such as booking a flight or managing a calendar—under various constraints via voice commands. Gemini 3.1 Flash Live achieved a score of 90.8%, a significant improvement over previous native audio models. This high level of accuracy suggests that the model can not only understand what is being said but can also translate those vocal instructions into complex digital actions with minimal error.
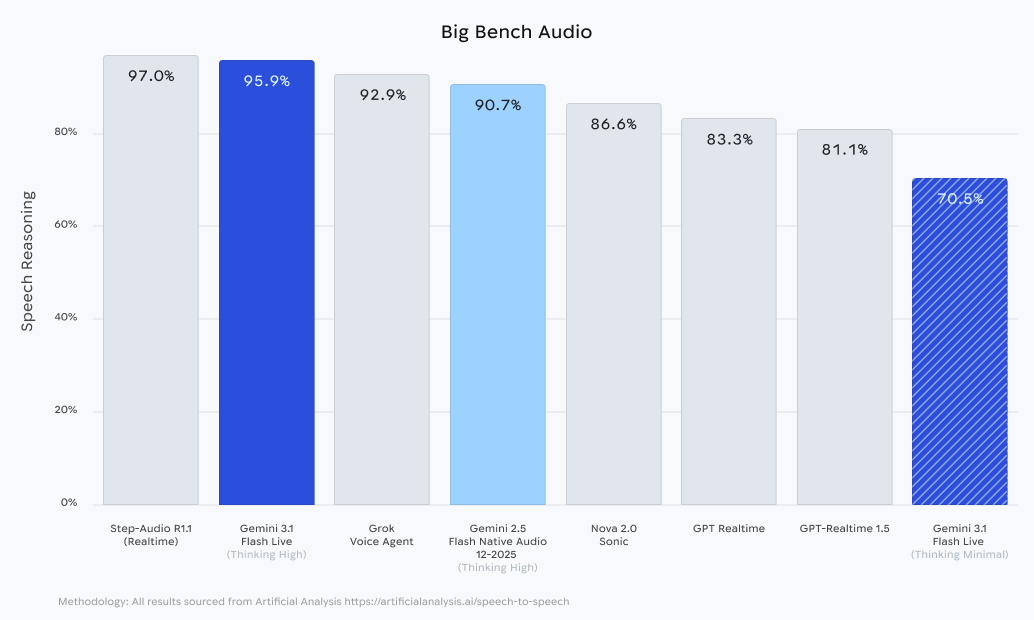
Furthermore, the model has shown exceptional results in Scale AI’s Audio MultiChallenge. This benchmark is particularly rigorous because it simulates real-world environments characterized by background noise, frequent interruptions, and the verbal hesitations (such as "um" or "uh") typical of human speech. When operating in its "thinking" mode—a state where the model allocates extra processing power to reason through complex instructions—Gemini 3.1 Flash Live leads the industry with a score of 36.1%. While this percentage may seem low in isolation, in the context of long-horizon reasoning within chaotic audio environments, it represents a substantial lead over existing multimodal models.
Enterprise Integration and Real-World Applications
The practical utility of Gemini 3.1 Flash Live is already being tested by several high-profile corporate partners. Companies such as Verizon, LiveKit, and The Home Depot have integrated the model into their workflows to enhance customer experience and operational efficiency. In enterprise settings, the model’s improved tonal understanding is a primary asset. It can detect acoustic nuances such as pitch, pace, and volume, allowing it to sense a customer’s emotional state.
For instance, in customer service applications, Gemini 3.1 Flash Live is capable of recognizing signs of frustration or confusion in a user’s voice. Rather than providing a generic scripted response, the model can dynamically adjust its tone and strategy to de-escalate the situation or offer more detailed explanations. This level of emotional intelligence, powered by what Google calls "2.5 Flash Native Audio" architecture, represents a move toward more empathetic AI agents.

In the realm of software development, the model supports "vibe coding"—a burgeoning trend where developers use natural language and voice to iterate on code and troubleshoot systems. By allowing developers to speak their logic and receive immediate, vocally articulated feedback, Gemini 3.1 Flash Live reduces the friction between conceptualizing an idea and executing it in a development environment.
Expanding Consumer Horizons: Gemini Live and Search Live
For the general public, the most immediate impact of the 3.1 Flash Live model is felt through Gemini Live and Search Live. Gemini Live, the mobile conversational interface, now offers faster response times and a significantly expanded "train of thought." Google reports that the model can now follow a conversation thread for twice as long as previous versions. This allows for more extended brainstorming sessions, such as planning a multi-city travel itinerary or debating a complex philosophical topic, without the AI losing the context of the earlier parts of the discussion.
The model’s inherent multilingual capabilities have also facilitated the global expansion of Search Live. This week, Google announced that Search Live is now available in over 200 countries and territories. This expansion allows users to engage in real-time, multimodal conversations with Google Search in their native languages. A user in Tokyo can now use their voice to ask about a specific landmark they are seeing through their camera lens, and the AI will provide a real-time audio response that incorporates both visual data and historical facts from the web.
Safety, Ethics, and the Implementation of SynthID
As AI-generated audio becomes increasingly indistinguishable from human speech, the potential for misuse—particularly in the form of deepfakes and misinformation—has become a central concern for regulators and technology companies alike. Google has addressed this by ensuring that all audio generated by Gemini 3.1 Flash Live is watermarked with SynthID.
SynthID, developed by the researchers at Google DeepMind, is a technology that embeds an imperceptible digital watermark directly into the audio waveform. This watermark does not affect the listening experience for humans, but it can be detected by specialized software, allowing platforms to identify content as AI-generated. By integrating SynthID into the core output of Gemini 3.1 Flash Live, Google is establishing a standard for transparency and accountability in the generative AI space. The company has also released a comprehensive "model card" detailing the safety evaluations and ethical guidelines followed during the model’s development.
Analysis of Industry Implications
The release of Gemini 3.1 Flash Live is a clear response to the intensifying competition in the AI sector, particularly from OpenAI’s GPT-4o and Apple’s Intelligence suite. The industry is moving away from a paradigm where users interact with "chatbots" toward a future of "AI agents" that can listen, see, and act autonomously.
By prioritizing low latency and natural rhythm, Google is positioning Gemini as the preferred platform for "ambient computing"—a world where AI is integrated into the environment and accessed through voice rather than screens. The ability of 3.1 Flash Live to handle complex function calling at a 90.8% success rate suggests that the era of the truly capable voice assistant is arriving. Previous iterations of voice assistants (such as the original Google Assistant or Amazon’s Alexa) were often limited to simple commands like setting timers or checking the weather. Gemini 3.1 Flash Live suggests a future where these assistants can handle nuanced negotiations, complex scheduling, and sophisticated technical support.
Moreover, the focus on enterprise-grade reliability ensures that Google maintains its stronghold in the cloud computing market through Vertex AI and Google AI Studio. By providing developers with the tools to build "voice-ready" agents that function in noisy, real-world environments, Google is fostering an ecosystem of third-party applications that will further entrench Gemini as a foundational technology.
Timeline and Availability
The rollout of Gemini 3.1 Flash Live is occurring across multiple tiers of Google’s service architecture. Starting today, developers can access the model via the Gemini Live API in Google AI Studio, providing them with the tools to build custom voice applications. Enterprise customers can leverage the model through the Gemini Enterprise for Customer Experience suite.
For consumers, the update is being pushed to the Gemini mobile app and integrated into Google Search. The global expansion to 200 countries is currently underway, with localization efforts continuing to ensure the model’s tonal and linguistic accuracy across diverse dialects and cultural contexts.
As the AI landscape continues to shift toward multimodal and real-time interactions, Gemini 3.1 Flash Live stands as a testament to the rapid pace of innovation. By combining high-precision reasoning with the fluidity of natural human speech, Google is not just improving a product; it is redefining the medium through which humans and machines communicate. The coming months will likely see a surge in new applications and use cases as the global community begins to interact with this more natural and reliable form of artificial intelligence.
