
Technical Specifications and Benchmark Performance
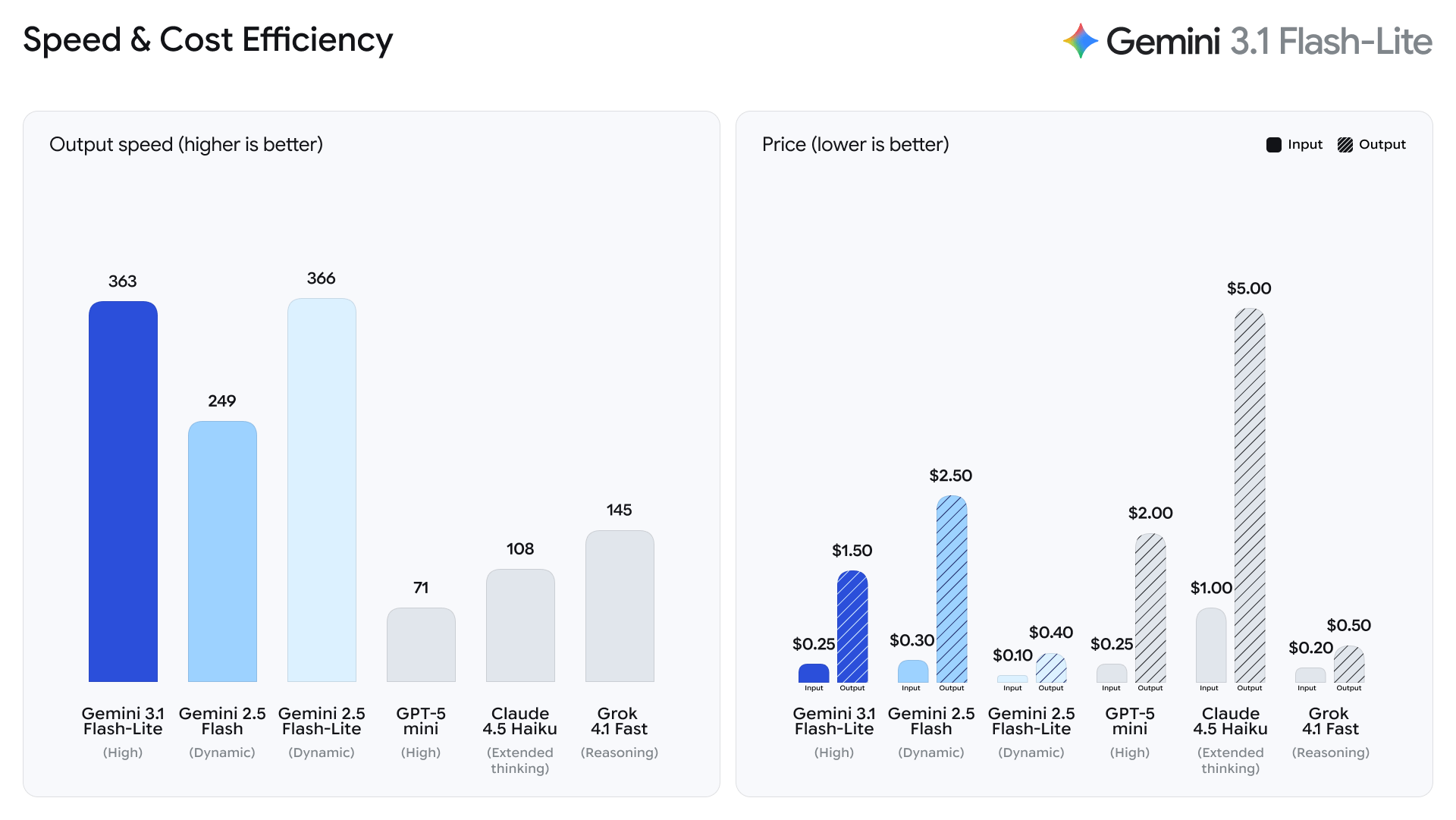
The primary value proposition of Gemini 3.1 Flash-Lite lies in its optimized architecture, which Google claims delivers best-in-class intelligence for high-frequency tasks. According to data provided by the Artificial Analysis benchmark, Gemini 3.1 Flash-Lite demonstrates a profound leap in speed over its predecessors. Specifically, the model achieves a 2.5-times faster "Time to First Answer Token" compared to Gemini 2.5 Flash. In the world of real-time applications—such as customer service chatbots or live translation tools—this reduction in latency is the difference between a seamless user experience and a disjointed one. Furthermore, the model has recorded a 45% increase in total output speed, allowing for the rapid generation of long-form content and complex data structures.
In terms of qualitative benchmarks, Gemini 3.1 Flash-Lite holds its own against significantly larger and more resource-intensive models. It currently boasts an Elo score of 1432 on the Arena.ai Leaderboard, a widely respected community-driven ranking system that utilizes blind human preference testing to determine model efficacy. On more academic and technical frontiers, the model scored 86.9% on the GPQA Diamond benchmark, which tests for graduate-level scientific reasoning, and 76.8% on the MMMU Pro benchmark, a multi-discipline task suite that requires high-level multimodal understanding. These figures indicate that while the model is "Lite" in name and cost, its reasoning capabilities often surpass the full-sized versions of previous-generation models like Gemini 2.5 Flash.
The Economics of AI: Pricing and Tokenization
One of the most disruptive aspects of the Gemini 3.1 Flash-Lite launch is its aggressive pricing structure. Google has positioned the model at $0.25 per one million input tokens and $1.50 per one million output tokens. To put this into context, this pricing strategy targets the "small language model" (SLM) market, directly competing with other efficiency-focused models like GPT-4o mini and Claude Haiku. By lowering the financial barrier to entry, Google is encouraging developers to shift from using AI for niche, one-off tasks to integrating it into the core, high-volume infrastructure of their applications.

For enterprises, this pricing model allows for the automation of "boring" but essential tasks that were previously too expensive to justify via LLMs. High-volume translation, massive-scale content moderation, and the constant monitoring of data streams for sentiment or compliance can now be processed at a fraction of the cost of Gemini 3.1 Pro or Ultra. This democratization of token costs is expected to catalyze a new wave of "AI-native" startups that rely on processing millions of queries daily.
Evolution of the Gemini Ecosystem: A Brief Chronology
The release of Gemini 3.1 Flash-Lite is the culmination of an intensive development cycle that began with the rebranding of Google’s AI efforts under the Gemini umbrella in early 2024.
- Gemini 1.0 and 1.5 (Early to Mid-2024): Google introduced the first native multimodal models, with the 1.5 Pro version making headlines for its massive 1-million-token context window. This era focused on "what" the AI could understand.
- Gemini 2.0 and 2.5 (Late 2024): The focus shifted toward efficiency and "Flash" models. Google recognized that while reasoning was important, speed was the primary bottleneck for developer adoption.
- Gemini 3.0 Series (Early 2025): The 3.0 series introduced enhanced reasoning and better adherence to complex instructions.
- Gemini 3.1 and Flash-Lite (Present): The current phase represents the refinement of the 3.0 architecture. Gemini 3.1 Flash-Lite is the "distilled" essence of the series, taking the learnings from the 3.1 Pro and Ultra models and shrinking them into a highly efficient package that retains a surprising amount of the original models’ "intellectual" depth.
Adaptive Intelligence and the "Thinking Levels" Feature
A standout feature accompanying Gemini 3.1 Flash-Lite is the introduction of "thinking levels" within Google AI Studio and Vertex AI. This functionality gives developers granular control over the model’s cognitive expenditure. For simple tasks like sorting a list or basic language translation, the model can be set to a "low-thinking" mode to prioritize maximum speed and minimum cost. Conversely, for tasks involving complex code generation, UI/UX dashboard simulation, or intricate instruction-following, developers can opt for higher "thinking" levels.
This adaptive intelligence is critical for managing high-frequency workloads where not every query requires the same level of depth. It allows a single model to serve multiple roles within an application—acting as a fast router for simple queries and a nuanced reasoner for more complex user inputs. This flexibility is a direct response to developer feedback calling for more "knobs and dials" to manage the trade-off between latency and accuracy.

Industry Adoption and Real-World Use Cases
Early-access testers and several prominent tech companies have already begun integrating Gemini 3.1 Flash-Lite into their production environments. Companies like Latitude, known for its AI-driven gaming experiences, and Cartwheel, an AI animation platform, have reported that the model’s reasoning capabilities allow them to maintain high-quality outputs while scaling to thousands of concurrent users.
Whering, a digital closet and personal styling app, has utilized the model to analyze and sort vast libraries of user-uploaded images. For Whering, the ability of Gemini 3.1 Flash-Lite to handle multimodal inputs—understanding both text and images simultaneously—at a "lite" price point has enabled them to offer personalized styling recommendations to a much broader user base than was previously possible with more expensive models.
Other emerging use cases for the model include:
- Content Moderation: Real-time scanning of user-generated content for community guideline violations.
- Dynamic UI Generation: Creating custom user interfaces on the fly based on user behavior and preferences.
- Scientific Simulation: Assisting researchers in running high-volume, low-complexity simulations to narrow down variables for more intensive study.
- Enterprise Search: Powering internal knowledge bases where thousands of documents must be indexed and queried daily.
Broader Implications and Market Impact
The launch of Gemini 3.1 Flash-Lite signals a broader shift in the AI industry away from the "bigger is better" philosophy. While the "frontier" models (like Gemini Ultra or GPT-5) continue to push the absolute limits of machine intelligence, the real economic battle is being fought in the "Flash" and "Lite" tiers. This is where the majority of commercial value will likely be captured in the coming years.

By providing a model that is 2.5 times faster than its own previous "fast" model, Google is placing significant pressure on its competitors, notably OpenAI and Anthropic. The competition is no longer just about which model can pass the Bar Exam, but which model can process a billion tokens for the lowest price with the least amount of lag. This "race to the bottom" in pricing, paired with a "race to the top" in efficiency, is a win for the developer ecosystem, as it lowers the overhead for AI integration and encourages experimentation.
Furthermore, the integration of Gemini 3.1 Flash-Lite into Vertex AI ensures that Google Cloud customers have a seamless path to move from prototyping in AI Studio to global scale on Google’s enterprise infrastructure. This vertical integration is a key component of Google’s strategy to reclaim its position as the primary destination for AI development.
Conclusion and Future Outlook
As Gemini 3.1 Flash-Lite moves from its current preview phase to general availability, the tech industry will be watching closely to see how it performs under the strain of truly global-scale workloads. Google has indicated that this is only the beginning of the 3.1 series’ rollout, with further optimizations and features expected in the coming months. For now, the model stands as a testament to the fact that intelligence does not always have to come at a premium price. By prioritizing "intelligence at scale," Google is not just releasing a new model; it is providing the infrastructure for the next generation of highly responsive, AI-integrated software. Developers are encouraged to begin testing the model today, as the shift toward low-latency, high-efficiency AI appears to be the definitive trend of the current technological era.
