

In a significant leap forward for multimodal artificial intelligence, Google has officially unveiled Gemini 3.1 Flash Live, its most advanced audio and voice model to date, designed to bridge the gap between human conversation and machine processing. This latest iteration of the Gemini family focuses on three critical pillars of digital communication: precision, lower latency, and the delivery of a more natural rhythmic flow. By optimizing the way AI processes acoustic nuances, Google aims to transform voice interactions from static, command-based exchanges into fluid, real-time dialogues that can handle complex reasoning and task execution across a variety of environments.
The launch of Gemini 3.1 Flash Live represents a strategic consolidation of Google’s AI capabilities, integrating high-speed processing with deep tonal understanding. The model is now being deployed across the company’s entire ecosystem, serving developers via Google AI Studio, enterprises through Gemini Enterprise for Customer Experience, and the general public through the global expansion of Gemini Live and Search Live.
The Evolution of Google’s Multimodal Strategy
The arrival of Gemini 3.1 Flash Live is the culmination of a rapid development cycle that began with the initial announcement of the Gemini architecture in late 2023. While early iterations of AI voice models often relied on a "text-to-speech" and "speech-to-text" pipeline—which introduced significant lag and stripped away emotional context—the 3.1 Flash Live model is built on a "native audio" foundation. This means the AI processes sound directly as an input and generates it as an output, bypassing the need for intermediate text translation.
This architectural shift follows the roadmap laid out during the Google I/O 2024 conference, where the company teased "Project Astra," a vision for a universal AI agent capable of seeing, hearing, and responding in real-time. Gemini 3.1 Flash Live serves as the production-ready engine for that vision, moving beyond the experimental phase into a tool capable of handling the rigors of commercial and consumer use.
Chronologically, this release follows the deployment of Gemini 1.5 Pro and 1.5 Flash. While the 1.5 series established the "long context" capabilities that allowed the AI to read entire books or analyze hours of video, the 3.1 Flash Live update focuses on "Live" interaction. It prioritizes the "time-to-first-token" in audio generation, ensuring that when a user speaks, the AI responds within milliseconds, mimicking the natural cadence of a human conversation partner.

Technical Benchmarks and Supporting Data
To validate the claims of improved reliability and reasoning, Google subjected Gemini 3.1 Flash Live to a series of rigorous industry benchmarks. The results indicate a substantial lead over previous models and competitors in handling complex, multi-step instructions delivered via voice.
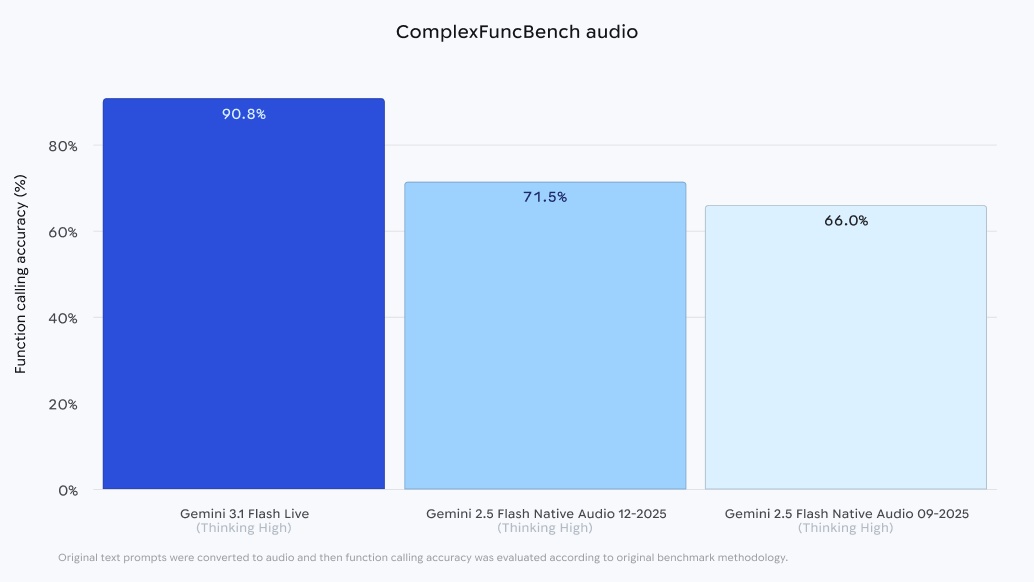
On the ComplexFuncBench Audio benchmark, which evaluates an AI’s ability to execute function calls—such as booking an appointment or checking a database while following specific constraints—Gemini 3.1 Flash Live achieved a score of 90.8%. This represents a significant improvement over previous-generation models, which often struggled to maintain logical consistency when faced with multiple, overlapping verbal commands.
Furthermore, the model’s reasoning capabilities were tested using Scale AI’s Audio MultiChallenge. This specific benchmark is designed to simulate real-world audio environments, complete with background noise, human hesitations, and interruptions. With its "thinking" mode activated—a feature that allows the model to process internal logic before generating an audible response—Gemini 3.1 Flash Live led the field with a score of 36.1%. While seemingly lower than text-based scores, in the context of long-horizon audio reasoning, this figure marks a high-water mark for the industry.
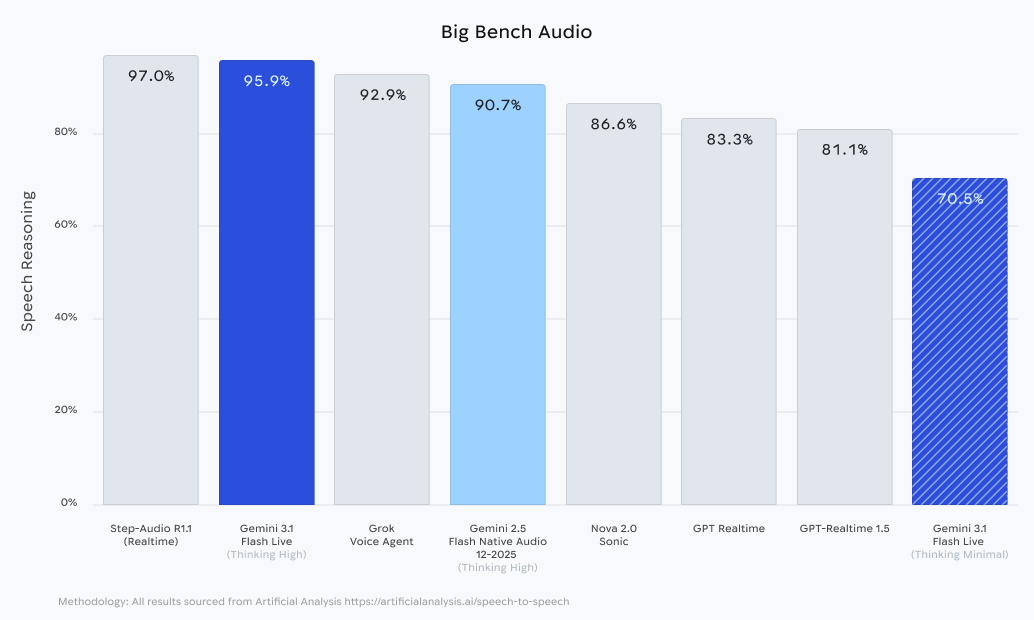
The model also showed improved performance on BigBenchAudio, demonstrating that it can follow complex instructions even when the audio input is less than perfect. For developers, these numbers translate to a more robust framework for building voice-ready agents that do not "break" when a user changes their mind mid-sentence or speaks in a noisy environment.
Enterprise Applications and Customer Experience
For the corporate sector, the implications of Gemini 3.1 Flash Live are particularly profound. Google has integrated this model into its Gemini Enterprise for Customer Experience suite, targeting industries that rely heavily on call centers and digital assistants.

A key breakthrough in this version is the model’s improved "tonal understanding." Unlike traditional AI, which might interpret a frustrated customer’s words literally, Gemini 3.1 Flash Live is engineered to recognize acoustic nuances such as pitch, pace, and volume. By detecting the subtle signs of frustration or confusion, the AI can dynamically adjust its response—softening its tone or offering more detailed explanations to de-escalate a situation.
Early adopters of the technology include major corporations such as Verizon, The Home Depot, and LiveKit. Verizon has explored using the model to streamline customer support workflows, while The Home Depot has looked at how natural voice dialogue can assist both employees and customers in navigating vast product inventories. Feedback from these partners has centered on the "naturalness" of the dialogue, with testers noting that the AI no longer feels like a scripted machine but rather a helpful, informed assistant.
Consumer Impact: Global Expansion and Search Live
While developers and enterprises gain a powerful tool, everyday users will notice the impact of Gemini 3.1 Flash Live through the massive expansion of Search Live. Google has announced that this week, Search Live is becoming available in more than 200 countries and territories.
This global rollout is made possible by the model’s inherent multilinguality. Gemini 3.1 Flash Live does not just translate languages; it understands the cultural and linguistic rhythms of different regions. This allows users to engage in multimodal conversations—using their voice and camera simultaneously—to solve problems. For example, a user in Japan could point their phone at a broken bicycle part and ask for troubleshooting help in Japanese, receiving a real-time, step-by-step audio guide that adjusts as the user performs the repair.
In addition to Search Live, the Gemini Live app has received a significant upgrade. The 3.1 Flash Live engine allows the AI to follow the thread of a conversation for twice as long as previous versions. This "extended memory" is crucial for brainstorming sessions or long-form storytelling, where the user might refer back to an idea mentioned ten minutes prior.
Safety, Responsibility, and the SynthID Framework
As AI-generated audio becomes indistinguishable from human speech, the potential for misuse—such as deepfakes or misinformation—has become a central concern for policymakers and tech leaders alike. In response, Google has implemented a comprehensive safety strategy centered on SynthID.
Developed by Google DeepMind, SynthID is a watermarking technology that is interwoven directly into the audio output of Gemini 3.1 Flash Live. This watermark is imperceptible to the human ear but can be detected by specialized software. By embedding this digital signature at the point of generation, Google provides a mechanism for platforms and users to verify whether an audio clip is AI-generated.
Valeria Wu, Product Manager, and Yifan Ding, Software Engineer on behalf of the Gemini team, emphasized in their technical disclosures that safety is not an "add-on" but a foundational component of the model. The model card for Gemini 3.1 Flash Live outlines the rigorous testing performed to ensure the AI adheres to safety guidelines, refusing to generate harmful content or engage in deceptive practices.
Industry Analysis: The Shift to Voice-First Computing
The release of Gemini 3.1 Flash Live signals a broader shift in the technology landscape toward "voice-first" computing. For decades, the keyboard and mouse have been the primary interfaces for human-computer interaction. However, as AI models become more capable of understanding the complexities of human speech, the industry is moving toward a future where "vibe coding" (using voice to iterate on software) and conversational search become the norm.
Market analysts suggest that Google’s rapid deployment of these models is a defensive and offensive move against competitors like OpenAI and Meta. By making the model available in 200 countries immediately, Google is leveraging its massive global infrastructure to set the standard for what a "live" AI experience should be.
The economic implications are also noteworthy. By reducing the latency and increasing the reliability of voice AI, Google is lowering the barrier to entry for small and medium-sized enterprises to deploy high-quality automated services. This could lead to a significant increase in the adoption of AI agents in sectors ranging from healthcare (for patient intake) to education (for personalized tutoring).
As Gemini 3.1 Flash Live begins its rollout today, the focus shifts from what the AI can do to how humans will choose to use it. With its blend of technical precision and human-like intuition, Google’s latest model is not just a tool for answering questions—it is a foundational step toward a world where the dialogue between man and machine is as seamless as a conversation between friends.
