
Google has officially announced the launch of Gemini 3.1 Flash TTS, a sophisticated text-to-speech (TTS) model designed to bridge the gap between robotic synthesis and human-like vocal performance. This latest iteration of Google’s audio technology represents a pivotal shift in the generative AI landscape, prioritizing not only the clarity of speech but the granular controllability of emotional delivery, pacing, and stylistic nuance. By integrating advanced natural language processing with high-fidelity audio generation, the Gemini 3.1 Flash TTS model aims to provide developers, enterprises, and creative professionals with a toolset capable of producing immersive, localized, and highly expressive audio content at a global scale.
The release marks a significant milestone in Google’s broader Gemini ecosystem. While previous models focused heavily on text and image modality, Gemini 3.1 Flash TTS emphasizes the "voice" of AI, offering a specialized solution for applications ranging from automated customer service and educational tools to sophisticated narrative storytelling in gaming and digital media. The model is currently being rolled out across Google’s primary developer platforms, including Google AI Studio, Vertex AI, and Google Vids, ensuring that its capabilities are accessible to a wide spectrum of users.
Technological Evolution and the Path to Gemini 3.1 Flash TTS
The journey to Gemini 3.1 Flash TTS is rooted in years of research conducted by Google DeepMind and the broader Google Research teams. Historically, synthetic speech relied on concatenative synthesis—the process of stringing together recorded fragments of human speech—which often resulted in a "choppy" or unnatural cadence. The advent of neural TTS, pioneered by models like WaveNet in 2016, revolutionized the industry by using deep neural networks to generate raw audio waveforms.
Gemini 3.1 Flash TTS represents the next logical step in this evolution. Unlike its predecessors, which often required complex Speech Synthesis Markup Language (SSML) to adjust tone or speed, the 3.1 Flash model introduces an intuitive "Audio Tags" system. This allows users to embed natural language commands directly into the text input. For example, a developer can direct the AI to speak with a specific emotional inflection or at a precise tempo without needing to master specialized coding languages. This shift toward "directed" AI speech mimics the relationship between a director and a voice actor, placing creative control back into the hands of the user.
The Architecture of "Flash" Models
The designation of "Flash" within the Gemini family signifies a specific architectural focus on speed, efficiency, and low latency. In the context of TTS, latency is the critical metric; for real-time applications like voice assistants or interactive gaming, any delay between text input and audio output can break the user’s immersion. Gemini 3.1 Flash TTS is optimized to deliver high-fidelity audio almost instantaneously, making it suitable for high-traffic enterprise environments where performance and cost-effectiveness are paramount.
By balancing computational efficiency with output quality, Google has positioned this model to be "production-ready." Enterprises can deploy the model at scale without the prohibitive costs traditionally associated with high-end generative audio. This economic accessibility is a cornerstone of Google’s strategy to democratize AI, allowing smaller startups to compete with larger tech firms in the burgeoning field of AI-driven audio experiences.

Performance Benchmarking and Industry Recognition
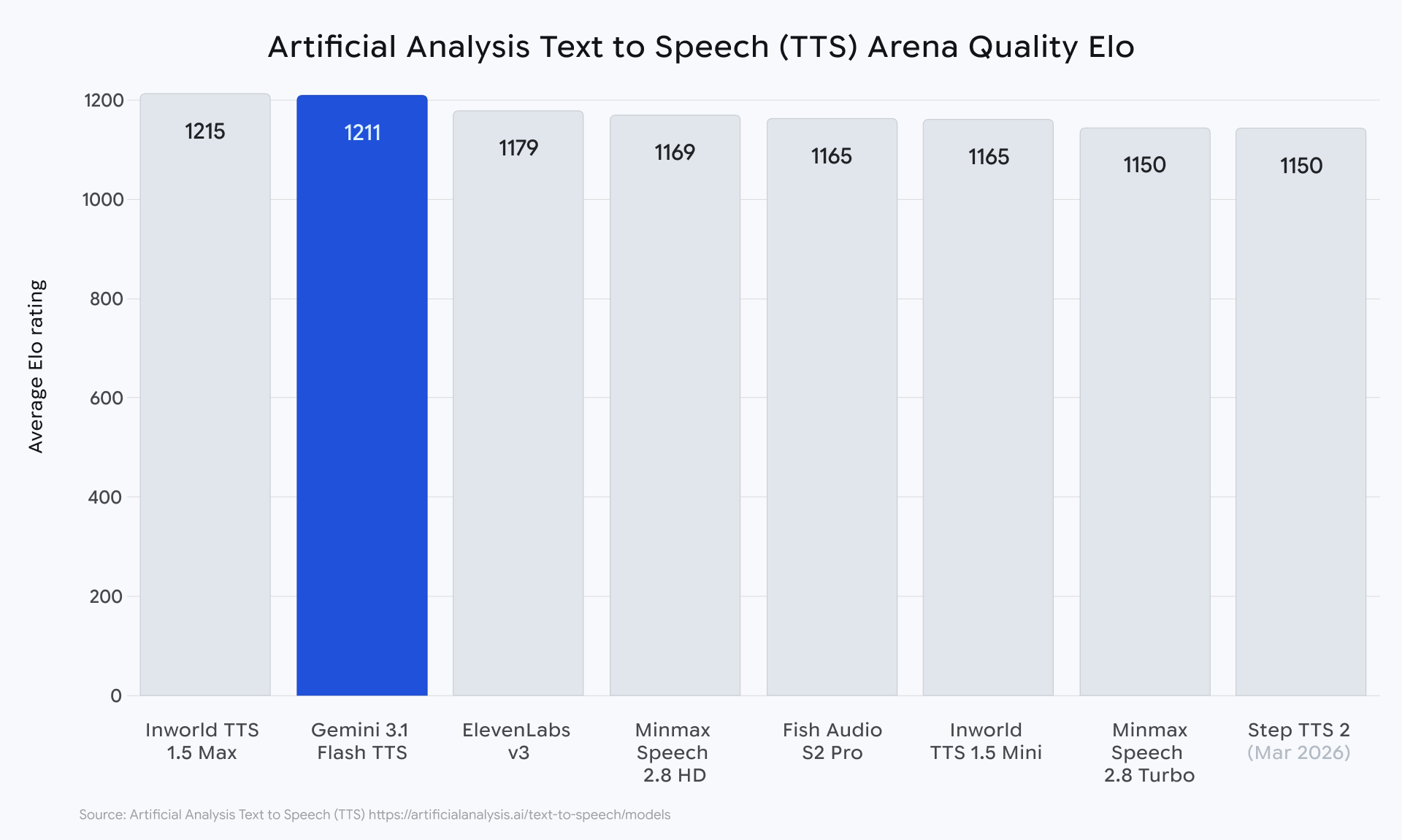
The quality of Gemini 3.1 Flash TTS has been validated by third-party benchmarks, most notably through Artificial Analysis, an independent organization that evaluates AI models. On the Artificial Analysis TTS leaderboard, which utilizes blind human preference testing to rank models, Gemini 3.1 Flash TTS achieved an Elo score of 1,211. This score reflects a high level of human preference, indicating that listeners find the model’s output to be significantly more natural and engaging than many competing technologies.
Furthermore, Artificial Analysis positioned the model in its "most attractive quadrant," a metric that plots quality against price. This ranking confirms that Google has successfully engineered a model that does not compromise on vocal richness despite its "Flash" optimization for speed and lower operational costs. The model’s ability to handle multi-speaker dialogues natively—allowing for seamless transitions between different "voices" in a single audio stream—further distinguishes it from traditional TTS engines that often struggle with conversational flow.
Granular Control via Audio Tags
One of the standout features of the 3.1 Flash TTS update is the introduction of granular audio tags. These tags function as metadata that instructs the model on how to interpret specific segments of text. In traditional systems, achieving a "whisper" or a "shout" required separate voice models or heavy post-production. With Gemini 3.1 Flash TTS, these variations can be triggered dynamically.
Key functionalities enabled by these tags include:
- Pacing and Tempo: Users can slow down complex instructions or speed up exciting dialogue to match the context of the content.
- Vocal Style: The model can shift between formal, authoritative tones for news delivery and casual, warm tones for personal assistants.
- Emotional Inflection: By interpreting natural language cues, the AI can inject subtle nuances into the speech, such as hesitation, excitement, or empathy.
This level of control is particularly beneficial for developers using Google AI Studio. The "director’s chair" approach allows for rapid prototyping, where a developer can tweak the performance of a digital character in real-time, significantly reducing the development cycle for audio-heavy applications.
Global Reach and Linguistic Diversity
In an increasingly globalized digital economy, the ability to communicate across linguistic barriers is essential. Gemini 3.1 Flash TTS launches with support for over 70 languages, covering a vast majority of the world’s spoken population. This is not merely a translation feature; the model is designed to respect the unique phonetic and tonal requirements of different languages.
For instance, the model’s optimizations include specific accent controls and localized pacing, ensuring that the AI sounds authentic to native speakers rather than like a translated version of an English voice. This capability is vital for multinational corporations that require consistent brand voices across different regions. Early enterprise testers have noted that the 3.1 Flash TTS model allows them to maintain high-quality vocal performances in markets that were previously underserved by high-end AI speech technology.

Safety, Ethics, and the Role of SynthID
As generative AI becomes more sophisticated, the risks associated with misinformation and "deepfakes" have grown. Google has addressed these concerns by integrating SynthID into all audio generated by Gemini 3.1 Flash TTS. SynthID is a cutting-edge watermarking technology developed by Google DeepMind that embeds an imperceptible digital signature directly into the audio waveform.
Unlike traditional metadata, which can be easily stripped or edited, the SynthID watermark remains detectable even after the audio has been compressed, edited, or recorded. This allows platforms and researchers to verify whether a piece of audio was generated by Google’s AI. By prioritizing transparency and traceability, Google aims to foster a safer digital environment where AI-generated content can be distinguished from human speech, thereby mitigating the potential for fraud or the spread of deceptive content.
Broader Implications for the AI Industry
The release of Gemini 3.1 Flash TTS is likely to trigger a new wave of innovation across several sectors. In the field of accessibility, more expressive and natural-sounding voices can significantly improve the experience for individuals with visual impairments or speech disabilities. In education, the ability to generate "acted" narrations for textbooks and tutorials can lead to higher engagement and better learning outcomes.
Furthermore, the competitive landscape of the "Voice AI" market is set to intensify. Companies such as ElevenLabs, OpenAI, and Amazon have all invested heavily in synthetic speech. Google’s move to offer a high-quality, low-cost, and highly controllable model through its existing cloud infrastructure (Vertex AI) puts significant pressure on niche providers to innovate. The integration of 3.1 Flash TTS into Google Vids—an AI-powered video creation app for work—suggests that Google sees speech as a core component of its productivity suite, rather than just a standalone developer tool.
Timeline and Availability
The rollout of Gemini 3.1 Flash TTS follows a rapid sequence of updates within the Gemini ecosystem.
- Late 2023: Introduction of the Gemini 1.0 series, establishing the multimodal foundation.
- Early 2024: Launch of Gemini 1.5 Pro and 1.5 Flash, focusing on long-context windows and efficiency.
- Current Phase: Integration of specialized audio capabilities via 3.1 Flash TTS.
Currently, developers can access the model through the Google AI Studio "Playground," where they can experiment with the new audio tags and configuration settings. Enterprise customers can leverage the model via Vertex AI for robust, scalable deployments. As the rollout continues, Google is expected to integrate these expressive voices into more consumer-facing products, potentially transforming how users interact with the Google Assistant and other voice-activated services.
Conclusion: The Future of Synthetic Dialogue
Gemini 3.1 Flash TTS represents more than just an incremental update to a speech engine; it is a fundamental shift toward "expressive intelligence." By providing the tools to direct AI speech with the same nuance as human communication, Google is enabling a future where digital interactions are indistinguishable from natural ones. The combination of high Elo scores, multi-language support, and the security of SynthID watermarking establishes a new standard for the industry. As developers begin to explore the "director’s chair" capabilities of this model, the next generation of AI applications will likely be defined by their ability to not just speak, but to communicate with purpose, emotion, and global resonance.
